I was reading this the other day. The article presents this peculiar quote:
"It is better to have 100 functions operate on one data structure than to have 10 functions operate on 10 data structures."
—Alan J. Perlis [1]
And then some thoughts and questions regarding the quote that seemed a bit ridiculous. But what does this seemingly ambiguous quote really mean?
After some thought, I've concluded that it's an apologia for Lisp's lists everywhere philosophy.
You can reduce the quote to:
It's better to have one extremely generic type than 10 incompatible types.
Python already does this: every object implements, surprise, an object interface that boils down to a bunch of magic methods.
On the other hand, Lisp has generic functions. What this mean is that there is a dispatch system that binds certain function implementations to certain data-structures. A data structure that is bound with specific actions (aka functions or methods) is what I call a type.
The idea of not having specialised data-structures is an illusion - if a function takes something as an input then you have assumed a specific data structure, not just a mere list. This is why I think it's worthwhile designing the data-structures before the actions you'll want to have in the system.
Sounds counter-intuitive, as actions make the system run, not the data-structures - it seems natural to map out the actions first. Alas, starting with data-structures first lets you easily see what actions you could have and what actions you can't. In other words, it gives you perspective on many things: hard constrains, data flow and dependencies.
Just the actions don't give you perspective on dependencies. Dependencies imply state. State implies data. They don't give you perspective on what the system can and can't do - actions depends on inputs, data in other words. To put it another way, data is the limiting factor on what actions you could have and what actions you could not.
Given Python's lax access to the innards of objects, a large part of your type's API is just the data-structure. Also, given Python's support for properties [2], a large part of your API could be something that looks like a data-structure. So it's worthwhile to look really hard at this aspect of software design in the early stages of your project.
Generality of types *
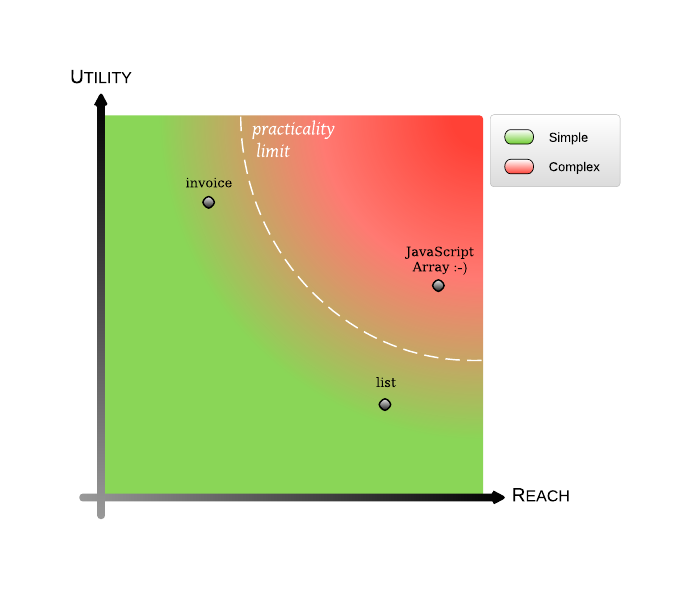
There are two main properties of types:
- Utility: How well does the type supports the consumer of said type. Does it have all the required actions? Is the API well suited or it makes the customer handle things that he should not be concerned with? Those are the key questions.
- Reach: How many distinct consumers can use this type. Does the type bring unwanted dependencies or concerns in the consumer? Does the type have many actions that go unused, and can't be used, by a large part of all the possible consumers?
To give examples few examples:
- A list has a very large reach and most of the time it fits fairly well consumers that just need a sequence-like type. However, the utility is very limited - you wouldn't use a list where you would use a higher level type, like an invoice.
- An invoice has a very limited reach, you can only use it in billing code. But the utility of it is tremendous - you wouldn't want to use a mere list - you'd burden your payment code with concerns that are better encapsulated in the invoice type.
There's a tradeoff in having both reach and utility: complexity vs re-usability. Something with reach and utility can be used in many places. However, complexity is bound to occur - handling all those disparate use-cases is taxing.
I'd even go as far to argue there's a hard limit to reaching both goals - pushing one goal limits the other, from the perspective of what you can have in an API.
If you can afford to change things later it's best to start with good utility and then move towards reach as use-cases arise. Otherwise you're at risk of over-engineering and wasting time both on development and maintenance.
What about the JavaScript Array? *
The Array object (as any other object in JavaScript) is very interesting problem from the perspective of the iterator interface. A for (var element in variable) block will iterate on whatever is there, both attributes and elements of the actual sequence. From this perspective the Array increases complexity (there's a cognitive burden, both on the implementers of the Array object and the users of it). If the Array would not allow attributes then this wouldn't be such an issue. But then the reach would be less.
On the other hand, you could in theory use an Array object as an invoice substitute, you could just slap the invoice fields like buyer, seller, total value, reference number etc on the Array object. So from this perspective it has higher utility than a plain list where you can't have arbitrary attributes (AttributeError: 'list' object has no attribute 'buyer').
Importance of data-structures *
So, you see, designing data-structures is tricky. There are tradeoffs to be made. If your data is wrongly designed then you'll have to compensate those flaws in your code. That means more code, crappy code, to maintain.
Interestingly, this has been well put almost 40 years ago:
"Show me your tables, and I won't usually need your flowchart; it'll be obvious."
—Fred Brooks, in Chapter 9 of The Mythical Man-Month [3]
The same thing, in more modern language:
"Show me your data structures, and I won't usually need your code; it'll be obvious."
—Eric Raymond, in The Cathedral and the Bazaar, paraphrasing Brooks [3]
Though it seems this isn't instilled in everyone's mind: some people actually think that you can accurately reason about business logic before reasoning about the data [4]. You can't reliably reason about logic if you don't know what data dependencies said logic has.
Chicken and egg *
There are situations where you can't know what data you need to store before you know what the actions are. So you'd be inclined to start thinking about all the actions first.
I prefer to sketch out a minimalistic data-structure and refine it as I become aware of what actions I need to support, making a note of what actions I have so far. This works reasonably well and allows me to easily see any redundancy or potential to generalize, or the need to specialize for that matter. In a way, this is similar to CRC cards but more profound.
Redundancy *
Starting with the data first allows you to easily see any redundancy in the data and make intelligent normalization choices.
Duplicated data-structures, especially the ones that are slightly different but distinct are a special kind of evil. They will frequently encourage, and sometimes even force the programmer to produce duplicated code, or code that tries to handle all the variances. It's very tempting because they are so similar. But alas, you can only think of so many things at the same time.
Even if you don't want to normalize your data, starting with the data first can result in synergy: the data from this place mixes or adapts well to the data from that other place. This synergy will reduce the amount of boilerplate and adapter code.
Closing thoughts *
Alan J. Perlis' principle can't be applied in all situations as the reach property is not always the imperative of software design and it has some disadvantages as illustrated above.
There are situations where none of these ideas apply (I don't mean to be complete):
- You don't have any data or your application is not data-centric, or there other more pressing things to consider first.
- You live in the perfect world of frozen requirements that are known before implementation.
| [1] | 9th quote: http://www.cs.yale.edu/homes/perlis-alan/quotes.html |
| [2] | Python allows you to implement transparent getters and setters via descriptors or the property builtin (which implements the descriptor interface). |
| [3] | (1, 2) http://www.dreamsongs.com/ObjectsHaveNotFailedNarr.html |
| [4] | A most peculiar remark: "As a symptom of this, I've interviewed candidates who, when presented with a simple OO business logic exercise, start by writing Django models. Please don't do this." —http://mauveweb.co.uk/posts/2014/08/organising-django-projects.html |